
Po krótkim wprowadzeniu do pozyskiwania i przechowywania danych czas przejść do analiz. Tematy muzyczne porzucam na bliżej nieokreślony czas by zająć Czytelników tym czym interesuję się od dłuższego czasu i z czym część z Was może Mnie kojarzyć - modelowanie preferencji i wyborów oraz modelowanie i prognozowanie wydarzeń sportowych.
Z punktu widzenia ekonometryka modelowanie wydarzeń sportowych oraz preferencji i wyborów mają ze sobą wiele wspólnego. W obydwu dziedzinach modeluje się najczęściej zdarzenia dyskretne, będące wynikiem konkurowania ze sobą określonych jednostek. Np. w piłce nożnej konkurują ze sobą dwie drużyny, gdzie zdarzeniem jest wynik w postaci wygranej drużyny A, remisu, bądź wygranej drużyny B. W teorii preferencji posłużę się książkowym (Greene) przykładem dotyczącym wyboru rodzaju transportu do podróży, gdzie konkurentami są samochód, samolot, pociąg i autobus. Celem Naszych poszukiwań jest ukryty zestaw parametrów reprezentujących jakość konkurujących ze sobą jednostek. Nie twierdzę jednak, że modelowanie wydarzeń sportowych niczym nie różni się od modelowania preferencji wyborów. Sport ma to do siebie, że jest w szczególny sposób zorganizowany, gdzie system rozgrywek z góry determinuje konfigurację próby, tym samym wymuszając stosowanie odpowiednich metod, a tych literatura naukowa dostarcza bardzo dużo.
Dzisiaj konkretnie, skupimy się na rozegranych dotychczas meczach Serie A w sezonie 2014/15, w celu wyłonienia statystycznej jakości drużyn uczestniczących w rozgrywkach.
Problem
Dlaczego mierzyć jakość drużyny, skoro drużyna potwierdza swoją jakość np. miejscem w tabeli? Dlatego, że liczba punktów nie jest współmierna do trudów jakie poczyniła drużyna, żeby je zdobyć. Liczba punktów nie wskazuje, z jakimi przeciwnikami drużyna się zmierzyła, z kim na wyjeździe, z kim na własnym boisku itd.. Jak za pomocą tabeli punktowej w sposób jasny określić różnicę w siłach dwóch drużyn? Czy drużyna mająca 50 pkt. jest pięciokrotnie lepsza od drużyny, która ma 10 pkt.? Czy w razie bezpośredniego starcia, szanse rozłożą się na 5:1? Na te pytania już odpowiedzieć trudniej. Wnioskowanie z takiej tabeli jest błędem wynikającym z przyjęcia z góry ustalonej skali (3 pkt. za zwycięstwo z kimkolwiek, 1 pkt. za remis z kimkolwiek), co w dalszym rozrachunku powoduje obciążone wnioski. Ja alternatywnie proponuję inne podejście.
Pierwszy ze sposobów, który chcę zaprezentować to model Bradley-Terry, którego sformułowanie przypisuje się E. Zermelo (1927) oraz R.A. Bradley i M.E. Terry (1952). Model BT ma postać:
$p_{i}=\frac{\pi_i}{\pi_i+\pi_j}$
$p_{j}=\frac{\pi_j}{\pi_i+\pi_j}$
gdzie:
$p_{i}$ prawdopodobieństwo zwycięstwa drużyny i-tej nad j-tą.
$\pi_{i}$ -siła drużyny i-tej, lokalizacje obiektu (drużyny) na skali preferencji.
$\pi_{j}$ - siła drużyny j-tej.
Formuła zakłada, że prawdopodobieństwo zwycięstwa jest uzależnione od proporcji siły drużyny w sumie sił obydwu konkurentów. Powyższa formuła zakłada zwycięstwo drużyny i-tej albo drużyny j-tej, bez uwzględniania remisów. Aby przerobić pierwotny model BT uwzględniając remisy, należałoby dokonać zmian w taki sposób aby remis w na skali preferencji wypadał pomiędzy przewagą drużyny i-tej, a przewagą drużyny j-tej. Taki sposób zaprezentował Rao i Kupper (1967), gdzie drużyna i-ta aby wygrać z drużyną j-tą musi mieć siłę większą od siły przeciwnika pewien współczynnik $\nu$, co można zauważyć poniżej:
$p_i=\frac{\pi_i}{\pi_i+\nu\pi_j}$
$p_j=\frac{\pi_j}{\nu\pi_i+\pi_j}$
$p_{remis}=1-p_j-p_i$
Roger R. Davidson (1970) zaproponwał poprawioną formułę, gdzie remis na skali preferencji wypada na geometrycznej średniej konkurujących ze sobą drużyn.
$p_{i}=\frac{\pi_i}{\pi_i+\pi_j+\nu \sqrt{\pi_i \pi_j}}$
Bardzo ważnym elementem w rozgrywkach sportowych jest tzw. atut własnego boiska, co można wyobrazić sobie jako $\theta$ - część składającą się na całkowitą siłę gospodarza.
$p_{i}=\frac{\theta \pi_i}{\theta \pi_i+\pi_j+\nu \sqrt{\theta \pi_i \pi_j}}$
Przyjmijmy również, że $a_i=log(\pi_i)$ przez co $a_i$ interpretowane będzie jako logarytm ilorazu szans, wtedy powyższy model będzie miał postać:
$p_i=\frac{e^{\theta+\beta_i}}{e^{\theta+\beta_i}+e^{\beta_j}+e^{\nu \frac{1}{2} (\theta+\beta_i+\beta_j)}}$
Powyższy model BT jest podstawowym, który może być wzbogacony o kolejne zmienne wedle uznania badacza. Model szacowany jest przy pomocy funkcji największej wiarygodności.
Rozwiązanie
Pierwszym Naszym zadaniem jest zapisanie formuły modelu za pomocą algorytmu R-owego. Należałoby w tym celu stworzyć wektor parametrów, będący punktem startowym funkcji optymalizującej - znajda się w nim dwa parametry theta-$\theta$ i nu-$\nu$ oraz k=20 parametrów odpowiadających za siłę drużyn $\beta_{drużyna}$. W funkcji znajdą się również dwie macierze zero-jedynkowe $H_{N,k}$ i $A_{N,k}$ z elementami $a_{n,j}$=1, gdy w meczu n-tym n={1,...,N} wystąpiła drużyna j-ta j={1,...,k}.
Funkcja zwraca macierz prawdopodobieństw wystąpienia wygranej gospodarza, remisu, zwycięstwa przyjezdnych, które następnie powinny być przekazane do funkcji liczącej logarytm wiarygodności.
Funkcje gotowe, teraz można przejść do danych z przykładu, które pobierzemy ze strony www.football-data.co.uk. Na stronie znajduje się pełen bukiet dobrze przygotowanych danych z kilku lig europejskich. W plikach oprócz samych rezultatów znajdują się również notowania bukmacherów na określone zdarzenia związane z poszczególnymi meczami. Zbiory są gotowe do analiz, z usystematyzowanymi nazwami kolumn.
Powyżej z zaciągniętych danych tworzymy wspomnianą wcześniej macierz A i H wyodrębniamy wektor z posortowanymi nazwami drużyn (druzyny) oraz wektor wyników (y) wg. schematu:
- "h" - wygrana gospodarza
- "t" - remis
- "a" - wygrana przyjezdznych
Do uruchomienia funkcji tworzymy jeszcze wektor parametrów (beta), o długości odpowiadającej liczbie drużyn z dwoma dodatkowymi parametrami $\nu$ i $\theta$. Wektor parametrów jest wypełniony jedynkami, co stanowi punkt startowy w procesie optymalizacji (zaleca się jednak wstawienie parametrów z liniowego modelu prawdopodobieństwa pomnożone przez *2,5). Do optymalizacji użyto funkcji optim() z metodą "BFGS". Zgodnie z poniższym, wartości początkowe parametrów przekazujemy jako pierwszy argument, kolejno fn=funkcja_którą_chcemy_minimalizować (ujemna suma logarytmów największej wiarygodności), a następnie dodatkowe obiekty (H i A), które chcemy przekazać "do środka". W wyniku optymalizacji otrzymujemy właściwe parametry.
Posiadając zoptymalizowane parametry możemy wywołać funkcję BT_Davidson w celu wyodrębnienia prawdopodobieństw wypadnięcia danego wyniku. W dalszym etapie stworzono graficzną prezentacje siły drużyn, wykorzystując ggplot2.
Posiadając zoptymalizowane parametry możemy wywołać funkcję BT_Davidson w celu wyodrębnienia prawdopodobieństw wypadnięcia danego wyniku. W dalszym etapie stworzono graficzną prezentacje siły drużyn, wykorzystując ggplot2.
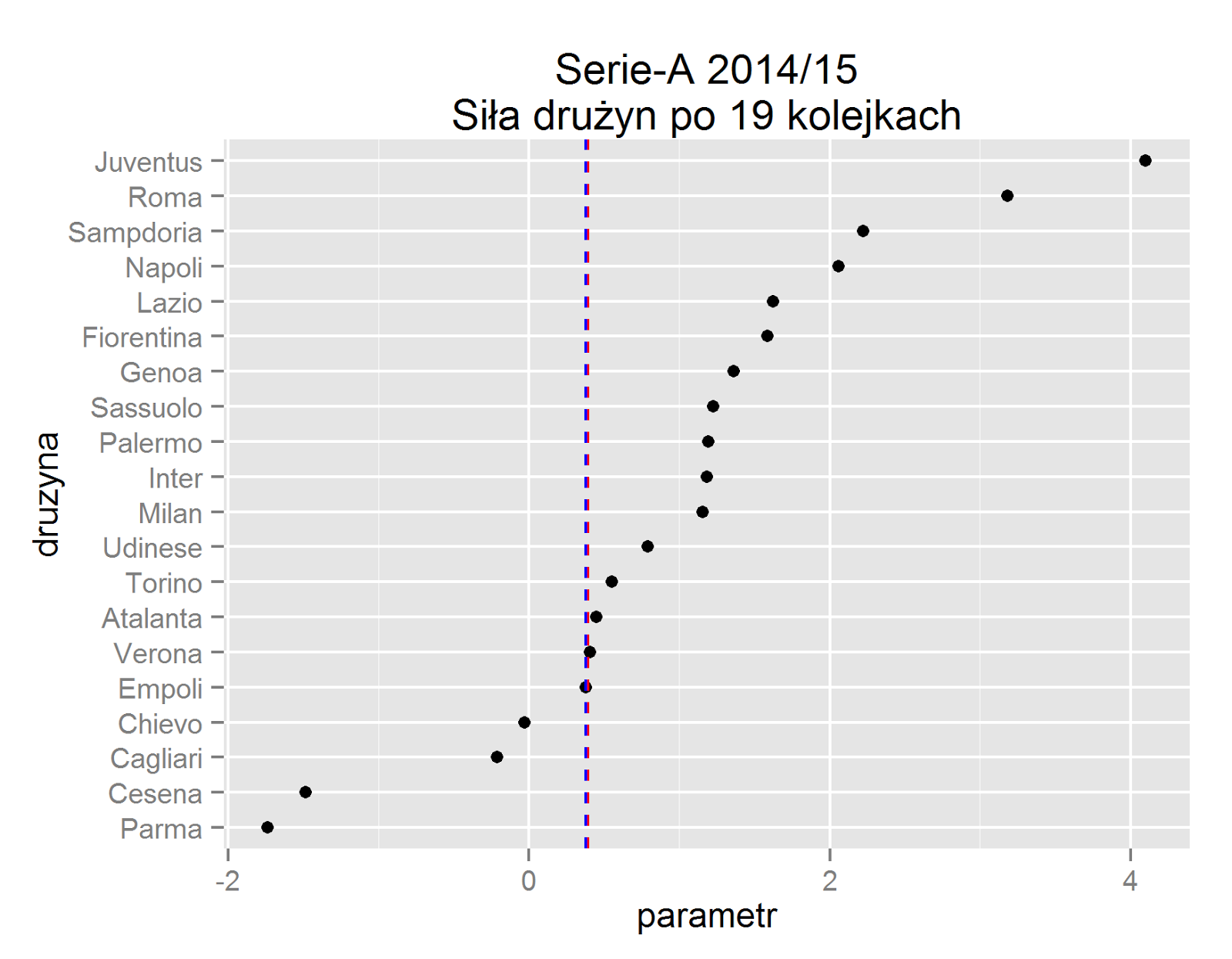
Parametry modelu BT interpretuje się tak samo jak parametry regresji logistycznej. Parametry $\beta$ określają siłę drużyn, kształtującą się w przedziale <-oo; +oo>, będąc logarytmem ilorazu szans zwycięstwa danej drużyny. Wykres pokazuje duży rozrzut między parametrami <-1.73; 4.10>, co jest ekstremalnie dużą różnicą w szansach drużyn. Najlepiej interpretować parametry jako eksponent, a różnica między parametrami np. $exp^{\beta_{Roma}}-exp^{\beta_{Napoli}}-1=15.28$ daje Romie, 15 krotnie wyższe szanse na zwycięstwo niż drużynie z Neapolu, zakładając, że mecz będzie na neutralnym terenie. Parametry $\theta$=0.37 i $\nu$=0.39 są dodatnie, co znaczy mają właściwe znaki.
Zamiast interpretować parametry szans w różnych konfiguracjach najlepiej dokonać prognozy na interesujące Nas pary drużyn. Poniżej wykonano prognozę 20 kolejki, zaplanowanej na najbliższy weekend wykorzystując oszacowany model. Prognoza w formie prawdopodobieństw przypisanych do poszczególnych rezultatów h-wygrana gospodarza, t-remis i a-wygrana przyjezdnych. Na czerwono zaznaczono prognozy meczów zakładając, że obstawiamy wynik o prawdopodobieństwie nie mniejszym niż 70%
| id | h | t | a | HT | AT |
|---|---|---|---|---|---|
| 1 | 50,41% | 37,09% | 12,50% | Cagliari | Sassuolo |
| 2 | 74,23% | 22,61% | 3,15% | Lazio | Milan |
| 3 | 47,84% | 38,19% | 13,96% | Verona | Atalanta |
| 4 | 61,18% | 31,43% | 7,40% | Inter | Torino |
| 5 | 85,36% | 13,64% | 1,00% | Juventus | Chievo |
| 6 | 4,10% | 25,17% | 70,73% | Parma | Cesena |
| 7 | 80,37% | 17,82% | 1,81% | Sampdoria | Palermo |
| 8 | 89,42% | 10,07% | 0,52% | Fiorentina | Roma |
| 9 | 52,72% | 36,01% | 11,27% | Empoli | Udinese |
| 10 | 80,43% | 17,77% | 1,80% | Napoli | Genoa |
Pomimo, ze istnieje pakiet, za pomocą którego możemy wykonać powyższą analizę, większą frajdę przyniosła samodzielna implementacja algorytmu. Dzisiejszy wpis można uznać za trening przed następnymi pozycjami z literatury naukowej, a tych przybywało w postępie wykładniczym. Sam R dostarcza Nam potężną liczbą pakietów co często pozwala na jedynie pobieżne zapoznanie się z syntax'em danych funkcji, zastosowaniami i interpretacją wyników, pomijając zupełnie podstawę funkcjonowania danego modelu. Muszę jednak napisać, że zaletą R jest dostępność i różnorodność zaimplementowanych analiz ale ta łatwość może nauczyć złych nawyków, a to "My jesteśmy kucharzami na tej imprezie".
Pełen skrypt dostępny tutaj
osobno funkcje z modelami
Pełen skrypt dostępny tutaj
osobno funkcje z modelami
Literatura:
1. Bradley, R. A. and Terry, M. E. (1952). Rank analysis of incomplete block designs. I. The method of paired comparisons. Biometrika 39 324–345.
2. Rao, P. V. and Kupper, L. L. (1967). Ties in paired-comparison experiments: A generalization of the Bradley–Terry model. J. Amer. Statist. Assoc. 62 194–204.
3. Roger R. Davidson (1970). On extending the Bradley-Terry model to accomodate ties in paired comparison experiments. FSU Statistics Report 169.
4. Zermelo, E. (1929). Die Berechnung der Turnier-Ergebnisse als ein Maximumproblem der Wahrscheinlichkeitsrechnung. Math. Z. 29 436–460
2. Rao, P. V. and Kupper, L. L. (1967). Ties in paired-comparison experiments: A generalization of the Bradley–Terry model. J. Amer. Statist. Assoc. 62 194–204.
3. Roger R. Davidson (1970). On extending the Bradley-Terry model to accomodate ties in paired comparison experiments. FSU Statistics Report 169.
4. Zermelo, E. (1929). Die Berechnung der Turnier-Ergebnisse als ein Maximumproblem der Wahrscheinlichkeitsrechnung. Math. Z. 29 436–460
Brak komentarzy:
Prześlij komentarz